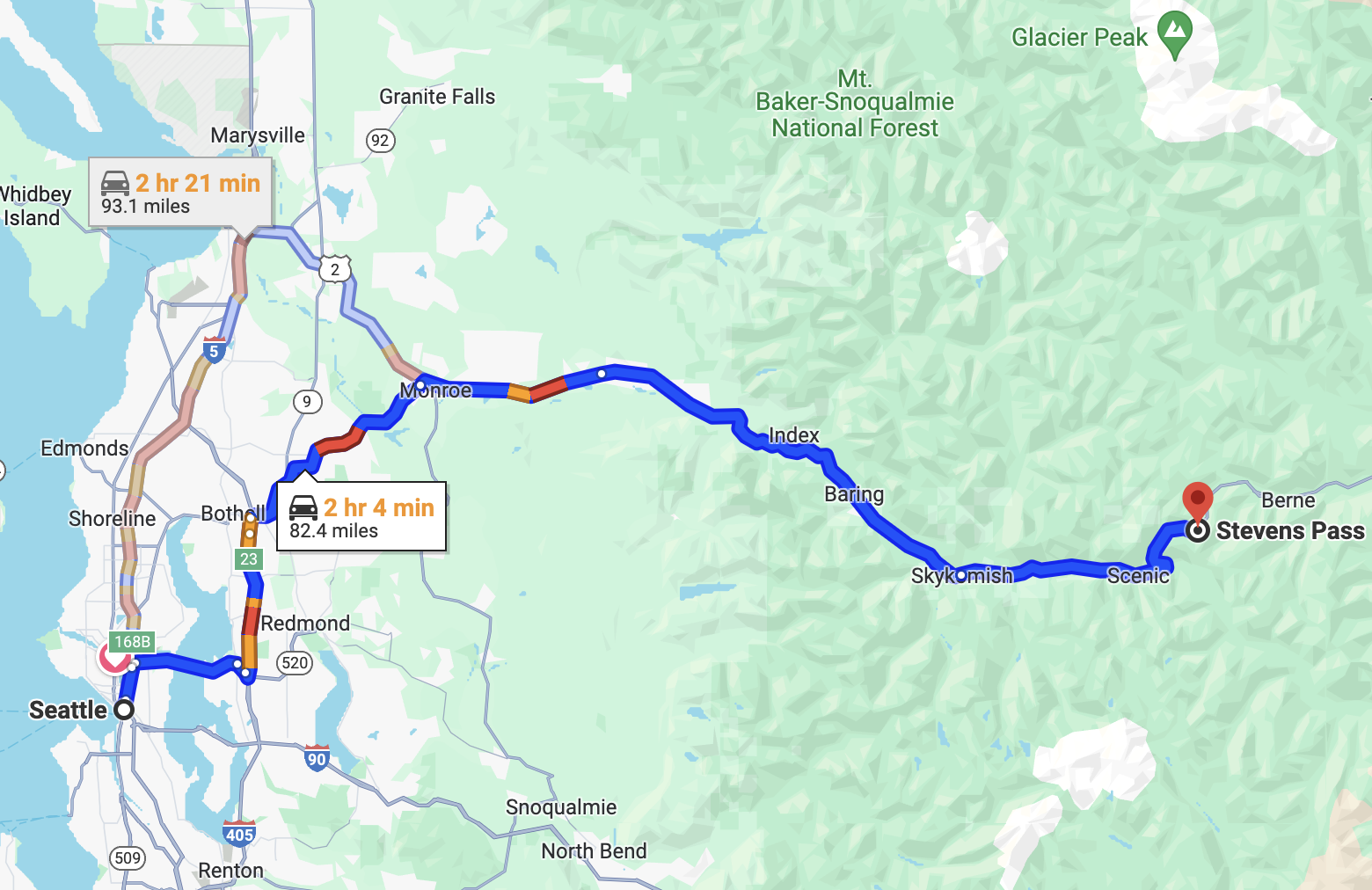
I bought an Epic Pass like so many other people in Seattle. I have been renewing it for the last 3 years. Here in Washington, the only place you can use it is Steven’s Pass which is a fine resort but it has some very specific problems for getting there.
- For one, it is 2 hours away from Seattle so it is quite the commitment to make a decision to drive there.
- The second notable aspect is that they have limited parking in a few lots next to the resort and then in an overflow lot about 20 miles down the other side of the mountain.
- If you don’t find parking at the upper lots you have to drive down the hill, park, then get a bus to take you back. This can add another 1-2 hours to your journey. Finally, there is a one-lane road for about half the journey. So if you go or leave at the same time as everyone else, you will run into significant traffic.
For this reason, I decided I wanted to build a very specific forecaster. I want it to tell me when I need to leave my house so that I can get parking at Stevens Pass given the day and time of day.
How I collected the dataset
To start with, I needed to know how much time it would take to drive from Seattle to Stevens pass. As it turns out you can get a URL from Google with the start and end destinations built in.
If you put it into a script like this: GitHub - Ministry of Product Forecaster
You can run the script against Google Maps and get a distance back with a little parsing.
I then put this all into a Docker instance and posted it to CloudRun. With some configuration, I was able to get it to append the results into a csv file in Google Cloud Storage.
I pulled the file down and posted it here in case you want to give it a try.
Here is my full repo: GitHub - Forecaster Repo
How much did the dataset cost?
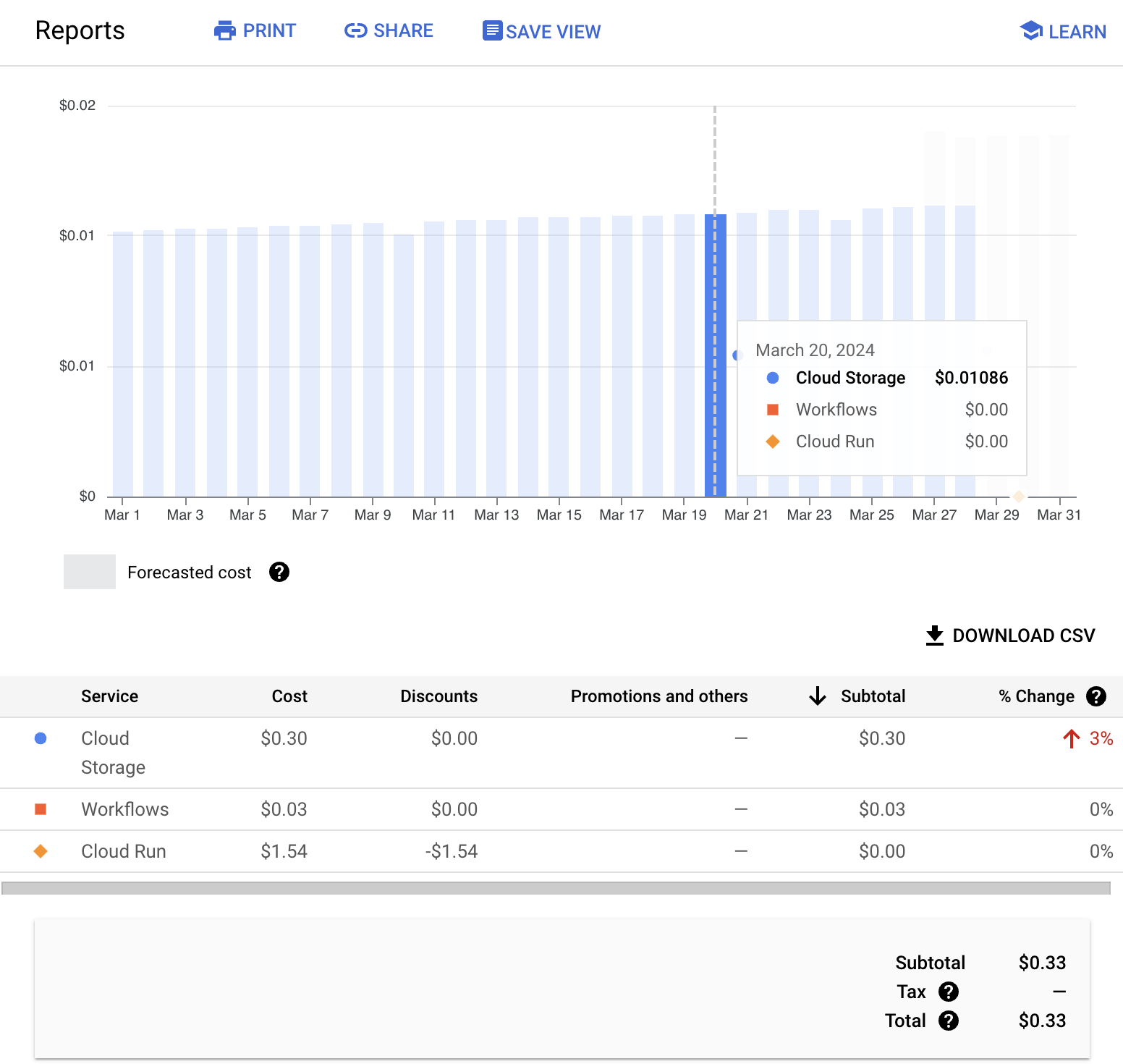
This is my first experience using GCP and I wasn’t quite sure what I signed up for. As it turns out, it was pretty cheap to build this dataset. However, it is clear that it will grow over time. This is a good lesson for future projects where I am putting together a time series dataset. I need to make sure that I am not growing it too quickly.
As it turns out, storage was the most expensive part. Generally costing, maybe $0.25 a month to store the resulting file which is still under 1 meg.
How did I do the forecast?
I used a Random Forest Regressor since the data involves both cyclic time-related features (like time of day and day of week) and potentially non-linear relationships between these features and the drive time. Generally, Random Forest can handle these complexities without needing the data to be linear and can also manage overfitting through its ensemble approach.
Another advantage of using Random Forest for this case is its interpretability in terms of feature importance, which can offer insights into how different times of day or days of the week affect drive times.
In this model I was able to achieve the following
- Mean Absolute Error: 3.25
- Mean Squared Error: 23.31
With a Mean Absolute Error (MAE) of 3.25 and a Mean Squared Error (MSE) of 23.31, the model seems to have a reasonable level of accuracy, given the context of predicting drive times. An MAE of 3.25 means that on average, the model’s predictions are within about 3.25 minutes of the actual drive times
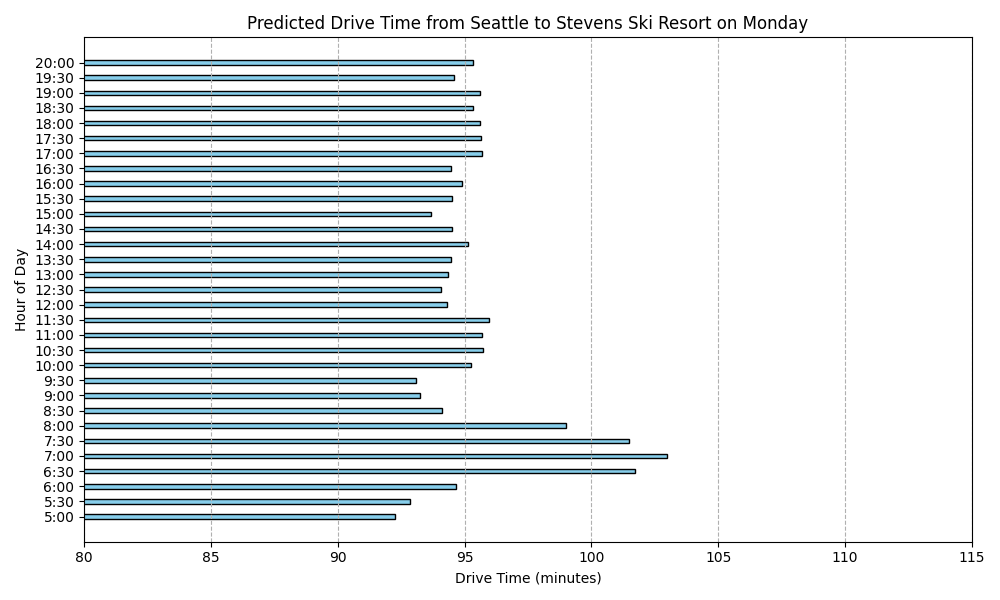
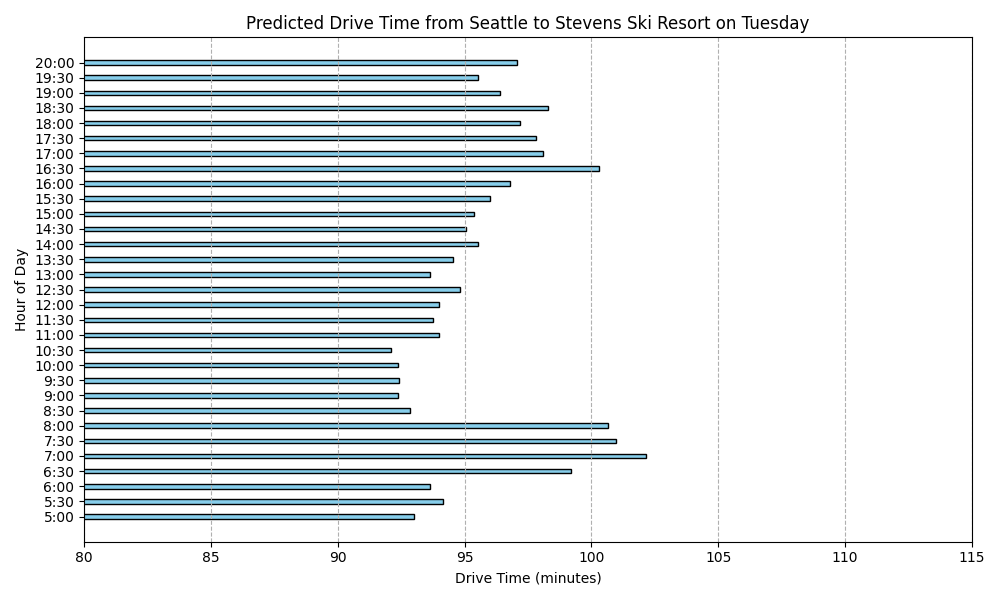
After that I used the model to predict what it would look like for each day of the week.
Predicted Drive Times from Seattle to Stevens Ski Resort
Here are the predicted drive times for each day of the week:
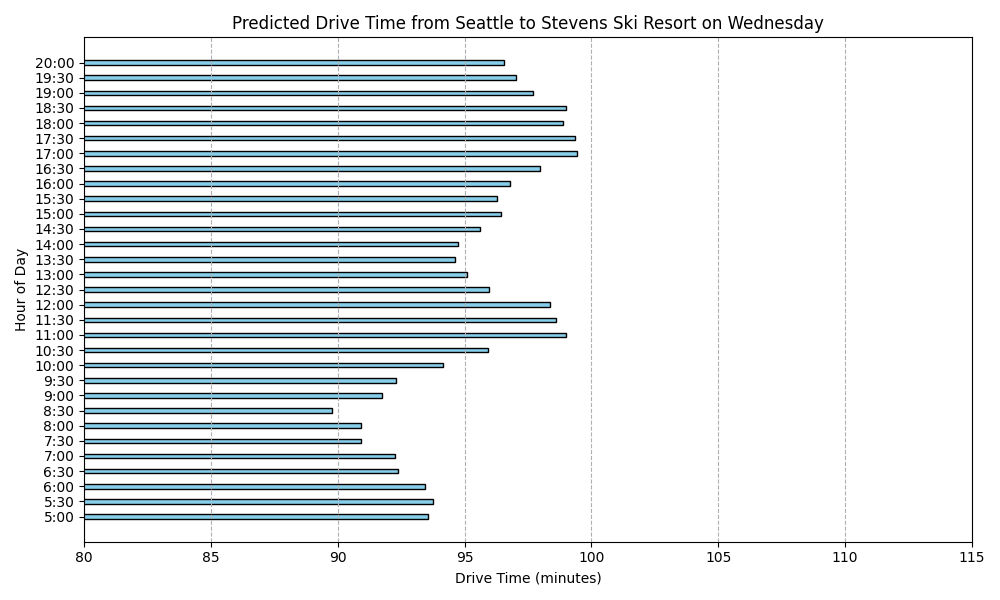
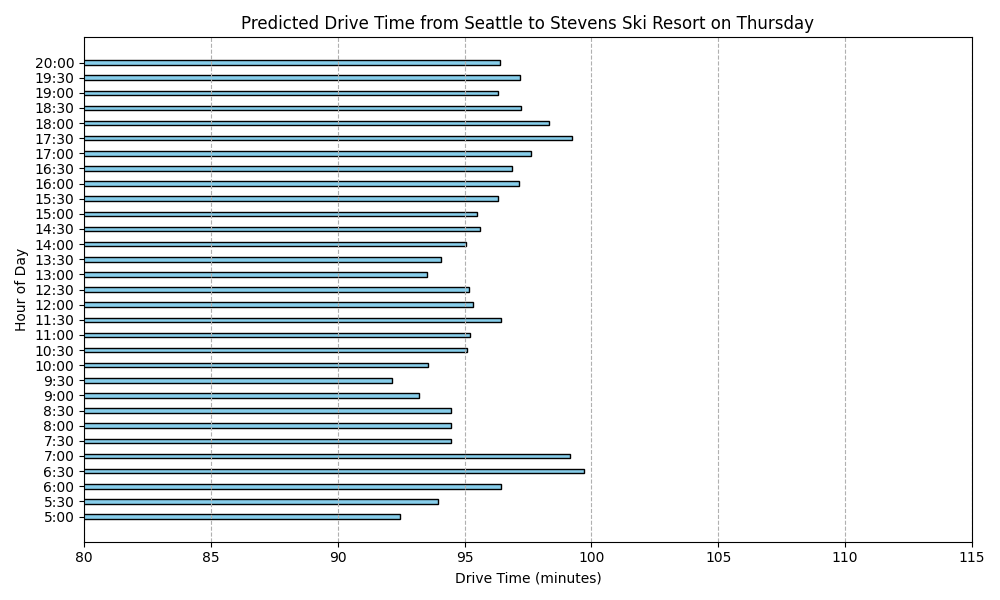
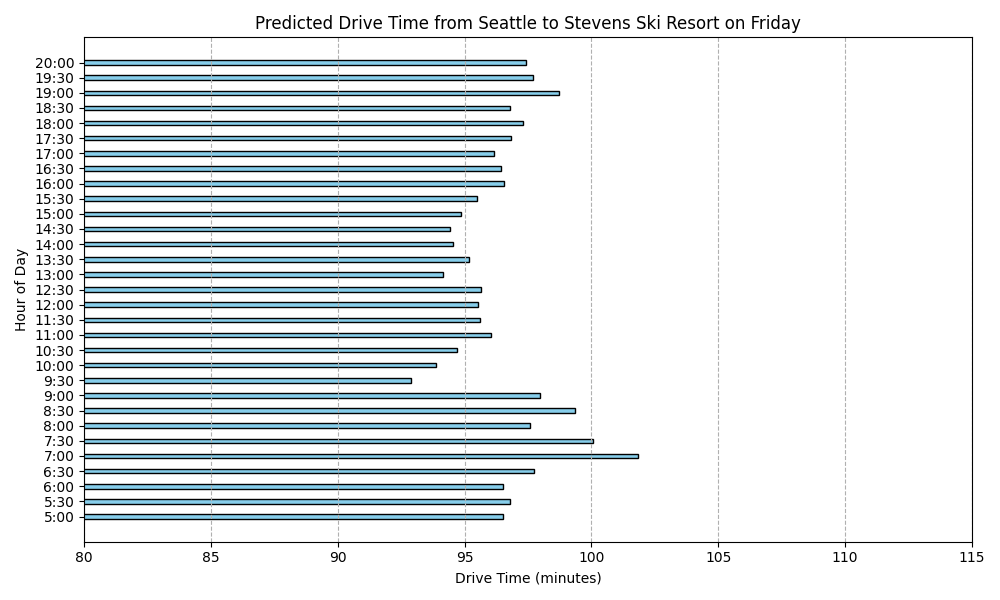
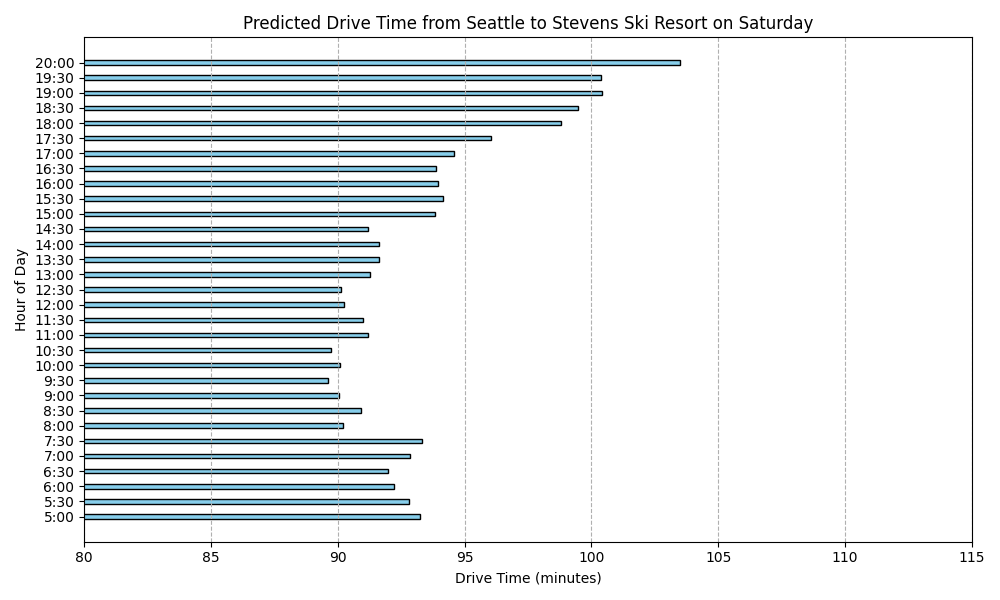
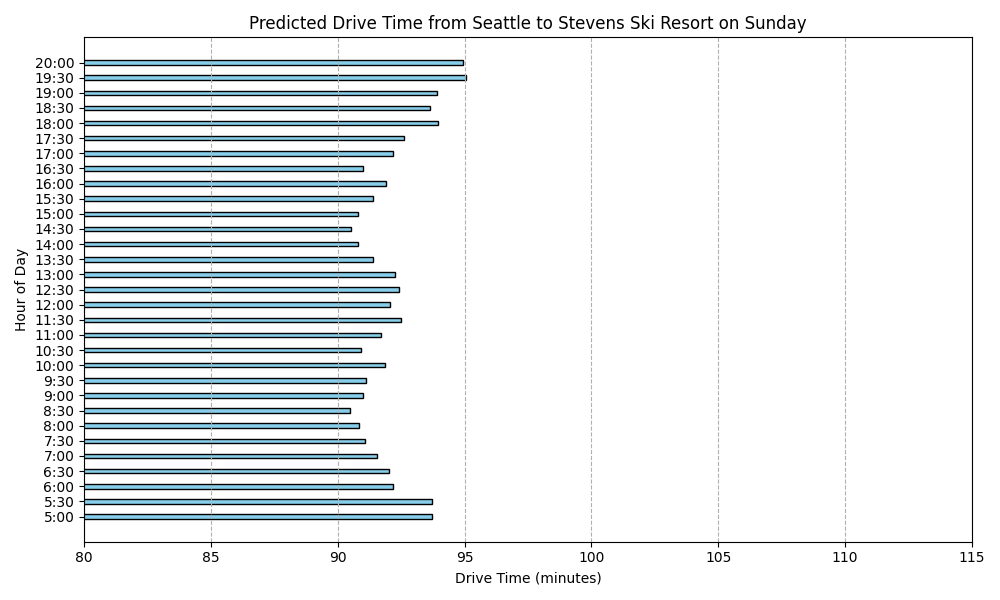
What stood out in this analysis?
For one, I’m suprised as to how there is such slow down period on Monday and Tuesday in the morning. I had thought I would see that sort of activity on Saturday and Sunday. I keep reviewing my code and I’m pretty sure I got the days of the week right. But I’m still suspicious.
I also can’t help but to look at this and see just the range is within 5 or 10 minutes difference. I realize that this is a prediction built from actual data over a several month period but it still seems to make this whole project seem moot because we are not talking about that much difference.
What would I do next time?
I had a lot of fun doing this analysis but I think I would do it differently in the future.
1. Track the return times from Stevens
I think it would be very interesting to predict the best times to leave, in particular because you run right into the same problems where traffic increases at the same time. The return drive is netorious for being hard to predict.
2. Adding other types of data to the dataset
In particular I would really like to add a column to represent the weather in the region. My guess is that ice and snow increases the drive time due to safety. It could also be that the number of drivers increases with good snow conditions thus increasing drive times. My guess is that we would actually see the morning drive time increase in that time.
3. Collect the drive times to the overflow parking
This could be the most interesting dataset. If we added a trace to the amount of time from one Stevens parking lot to the other I bet we would start to see when the overflow lot starts to be used. This would be an excellent source to recognize when the resort was being used heavily.
4. Image analysis of the lines at Stevens
Stevens publishes webcam images of the lines. I have considered having a vision recognition system watch the lines and determine when the greatest usage is, then track that as another column to enrich the datase.
5. Use a SARIMAX model
When the dataset gets larger and more complex, capturing intricate time series patterns or seasonal trends over a long period might be lost on the Random Forest Regressor. I might consider models more specifically tailored to time series forecasting that can incorporate external regressors, such as SARIMAX (Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors) or even LSTM (Long Short-Term Memory networks) for deep learning approaches.
Conclusion
Overall I think this project was a lot of fun for just creating a dataset and seeing what I could do with it. It is clearly not rich enough to be useful beyond my on intution. Basically leave around 6:30 am on a weekend if you want to make sure you have a parking spot.
I do think there is a world of personalized forecasting that hasn’t been thought out yet. For instance, if you have a specific commute, when is the best time to leave? We all develop these mental models but it would be nice to use some of the Google Maps historical drive times to help us optimize.